
在计算机视觉算法开发过程中,你是否需要从硬盘加载数据集、在图像或视频上绘制分类检测结果、选择视频中的特定区域进行分析,或者统计一个区域内目标的流量分析。如果有上述需求,那么文中这款计算机视觉工具箱绝对可以帮你事半功倍!
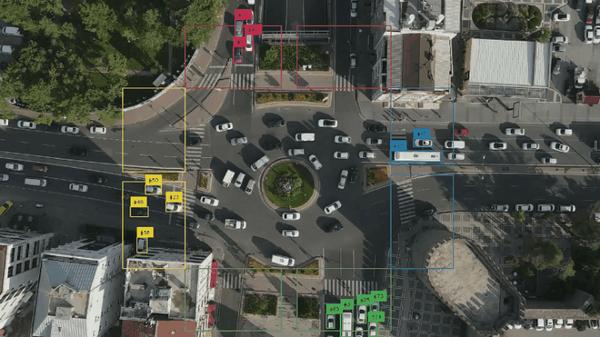
视频指定区域车流量计数
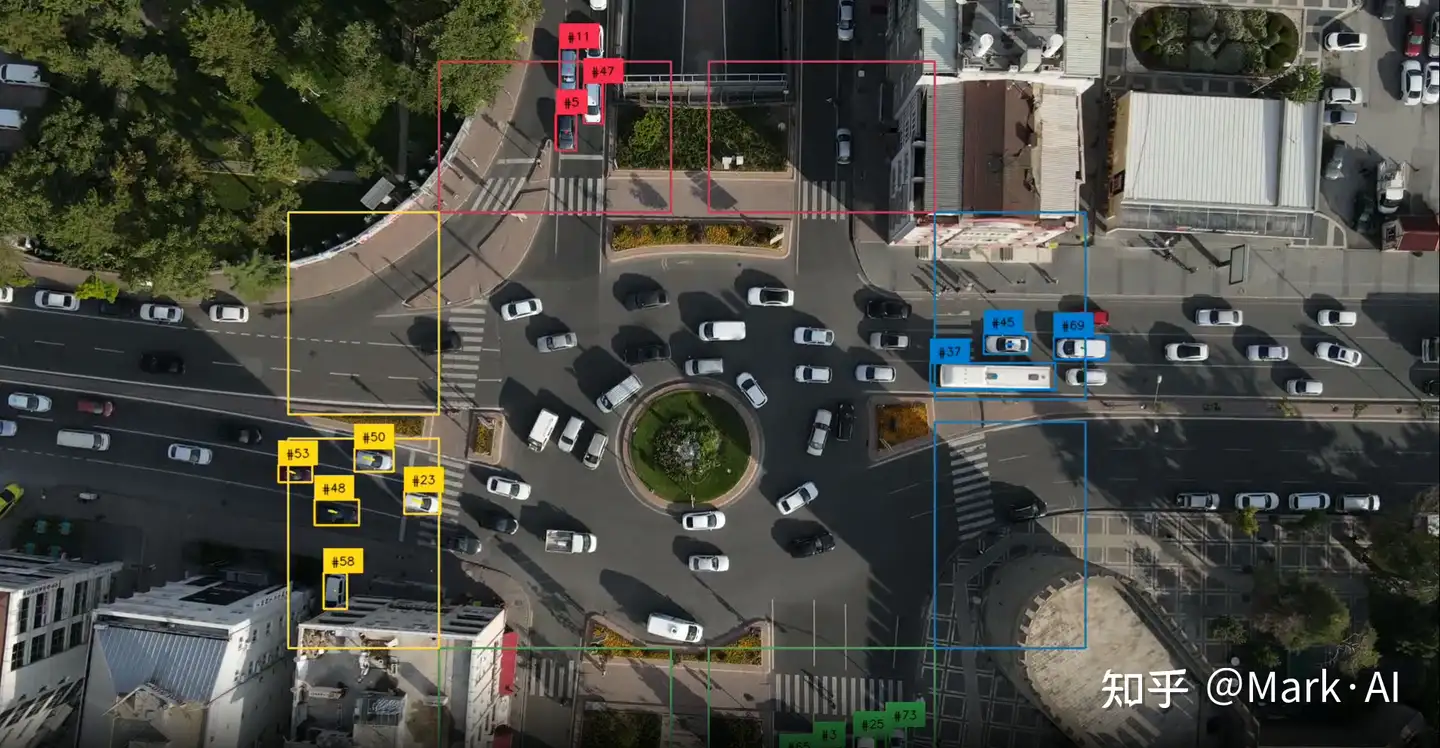
视频指定区域分析
# 一、 Supervision 计算机视觉工具箱
Supervision 工具简化了目标检测、分类、标注、跟踪等计算机视觉的开发流程。开发者仅需加载数据集和模型,就能轻松实现对图像和视频进行检测、统计某区域的被检测数量等操作。
除此之外,Supervision 被设计的与模型和框架完全解耦,可以支持 Ultralytics、Transformers 或 MMDetection 等优异开源库模型的直接导入。具体支持以下框架:
from_deepsparse (Deepsparse) | |
from_deepsparse (Deepsparse) | |
from_detectron2 (Detectron2) | |
from_mmdetection (MMDetection) | |
from_inference (Roboflow Inference) | |
from_sam (Segment Anything Model) | |
from_transformers (HuggingFace Transformers) | |
from_yolo_nas (YOLO-NAS) |
安装方式也很简单,Python 版本大于 3.8,可直接安装
pip install supervision |
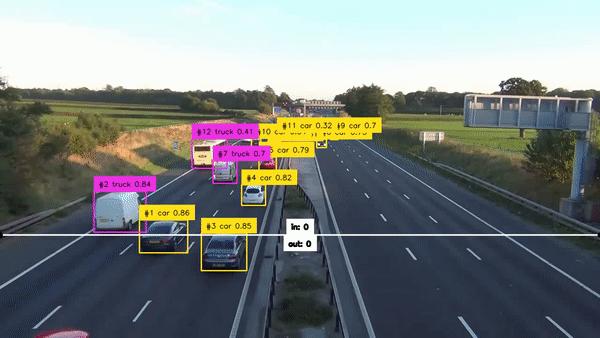
# 01. 在图像或视频上绘制分类检测结果
Supervision 提供了一种简化的解决方案,可以轻松地渲染一系列目标检测和分割模型的预测结果。接下来用少量的几行代码演示如何使用 YOLOv8 模型与 Ultralytics 包执行推理。
import cv2 | |
import supervision as sv | |
from ultralytics import YOLO | |
model = YOLO("yolov8s.pt") | |
image = cv2.imread(<PATH TO IMAGE>) | |
results = model(image)[0] | |
detections = sv.Detections.from_ultralytics(results) | |
>> ('detections', 4) | |
box_annotator = sv.BoxAnnotator() | |
annotated_image = box_annotator.annotate(image.copy(), detections=detections) | |
sv.plot_image(image=annotated_image, size=(8, 8)) | |
mask_annotator = sv.MaskAnnotator(color_lookup=sv.ColorLookup.INDEX) | |
annotated_image = mask_annotator.annotate(image.copy(), detections=detections) | |
sv.plot_image(image=annotated_image, size=(8, 8)) |

工具同时也支持分割结果的渲染,如下图
mask_annotator = sv.MaskAnnotator(color_lookup=sv.ColorLookup.INDEX) | |
annotated_image = mask_annotator.annotate(image.copy(), detections=detections) | |
sv.plot_image(image=annotated_image, size=(8, 8)) |

除此之外还可以非常方便的做一些后处理,可以按照概率,按照类别,按照一些组合逻辑进行筛选,让我们在渲染显示结果的代码开发上省了大量的工作。
import supervision as sv | |
detections = sv.Detections(...) | |
detections = detections[detections.class_id == 0] |

# 02. 数据集 API:从硬盘加载数据集及数据集转换
Supervision 提供了一组实用程序,允许以受支持的格式加载、拆分、合并和保存数据集。直接上代码:
>>> import supervision as sv | |
# 导入不同格式的数据集,如 cooc 或者 voc | |
>>> dataset = sv.DetectionDataset.from_pascal_voc( | |
... images_directory_path=..., | |
... annotations_directory_path=... | |
... ) | |
>>> dataset = sv.DetectionDataset.from_coco( | |
... images_directory_path=..., | |
... annotations_path=... | |
... ) | |
>>> dataset.classes | |
['dog', 'person'] | |
>>> len(dataset) | |
1000 | |
# 两行代码搞定数据集的划分 | |
>>> train_dataset, test_dataset = dataset.split(split_ratio=0.7) | |
>>> test_dataset, valid_dataset = test_dataset.split(split_ratio=0.5) | |
>>> len(train_dataset), len(test_dataset), len(valid_dataset) | |
(700, 150, 150) | |
# 数据集的合并 | |
>>> ds_1 = sv.DetectionDataset(...) | |
>>> ds_1.classes | |
['dog', 'person'] | |
>>> ds_2 = sv.DetectionDataset(...) | |
>>> ds_2.classes | |
['cat'] | |
>>> ds_merged = sv.DetectionDataset.merge([ds_1, ds_2]) | |
>>> ds_merged.classes | |
['cat', 'dog', 'person'] | |
# 数据集格式的转换 | |
>>> sv.DetectionDataset.from_yolo( | |
... images_directory_path=..., | |
... annotations_directory_path=..., | |
... data_yaml_path=... | |
... ).as_pascal_voc( | |
... images_directory_path=..., | |
... annotations_directory_path=... | |
... ) |
# 二、Supervision 更新的 <高级视频分析> 功能
# 01. 视频跟踪器
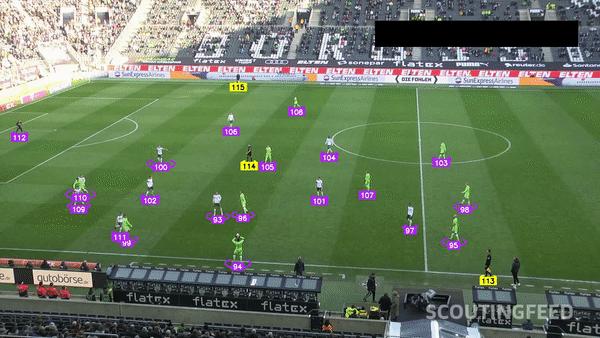
** 可以在视频中追踪物体的移动。**Supervision 运行推理并获得预测后,下一步是跟踪整个视频中检测到的对象。利用监督 sv.ByteTrack 功能,每个检测到的对象都被分配一个唯一的跟踪器 ID,从而能够在不同帧上连续跟踪对象的运动路径。
举例说明:想象一下,你正在观看一场足球比赛的录像。视频跟踪器可以帮助你追踪球员的移动,甚至分析他们的表现。
# 02. 区域工具
** 可以让你选择视频中的特定区域进行分析。** 举例说明: 如果你想统计路口的车流量,可以直接使用区域工具划定区域从而专注于指定区域的分析。
# 03. 注释器
** 可以让你在视频上添加文字、标签或其他信息。** 举例说明: 想象你正在制作一个烹饪教程视频。注释器可以让你在视频上添加食材名称、烹饪时间等信息,让观众更容易跟随。

# 三、 Supervision 项目源码
项目源码
项目主页
推荐
- 顶配版 SAM:由分割一切 - 升级至识别一切 - 再进化为感知一切
- 多模态大模型与深度学习高阶面试题:新颖、高频且有深度,数百道题覆盖六大专题
- 顶配版 OCR 工具!支持任何语言、任意表格、图表与文档的文本检测和识别工具